PyTorch基础——Numpy
第一部分
Numpy基础
什么是Numpy?
NumPy(Numerical Python的简称)是一个开源的Python库,用于进行科学计算。它提供了一个强大的N维数组对象,以及大量的函数用于处理这些数组。NumPy的主要功能包括:
- 多维数组对象:NumPy的核心功能是其多维数组对象(ndarray)。这是一个快速、灵活的容器,可以容纳大量同类型数据,使你能够对这些数据进行数学运算。
- 广播功能:NumPy提供了广播功能,这是一种强大的机制,允许NumPy在执行算术运算时处理不同形状的数组。
- 数学函数:NumPy提供了大量的数学函数,可以对数组中的元素进行各种数学运算,如加、减、乘、除、平方根等。
- 线性代数:NumPy包含了线性代数函数库,可以进行矩阵乘法、求逆、解线性方程,傅里叶变换等操作。
- 随机数生成:NumPy提供了生成各种随机数的功能,如均匀分布、正态分布等。
- 更方便的读取\写入磁盘上的阵列数据和操作存储映像文件的工具。
NumPy是许多科学计算库(如Pandas、Matplotlib、SciPy等)的基础库,也是机器学习和数据科学中常用的库。在深度学习中图像、声音、文本等输入数据最终都要转换为数组或矩阵,NumPy的多维数组可以用来表示向量、矩阵和张量,这些都是深度学习算法的基本构成元素。
为什么要使用Numpy
实际上python包含多个数据类型,数值类型(int,float,complex)、布尔类型(bool)、字符串(str)、列表(list)、元组(tuple)、字典(dict,{‘name’:’chenli’,’age’: 114514})、集合(set{})。
python包含这么多的数据类型,其中的列表(list)和数组(array)为什么不能用?原因是对于大数据来说,这些结构有很多不足。比如由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针。例如为了存储[1,2,3],就需要3个指针和3个整数对象,这样对于数值运算来讲,严重浪费了计算机中的内存和CPU或GPU的算力。对于array,它可以直接保存数值,但是它不支持多维,并且对应操作的函数也不多,因此也不适合。
怎么使用Numpy?
第一步使用 pip install numpy 来下载numpy库。
生成Numpy数组。
1
2
3
4
5import numpy as np
lst1= [[3.14, 2.17,0,1,2],[1,2,3,4,5]] # 一个二维列表
nd1 = np.array(lst1)# 使用np.array()将列表数据类型转换成np数据类型
print(nd1) # 显示的结果为一个二维列表
print(type(nd1)) # 显示结果为<class 'numpy.ndarray'>numpy中的random模块生成数组
1
2
3
4
5
6
7
8
9import numpy as np
nd1 = np.random.random([3,3]) # 产生一个[3,3]ndarray,范围为0-1之间的随机数。
np.random.seed(123) # 为了每次生成同一份数据,可以指定一个随机种子,而后生成的随机数据是固定的。
nd2 = np.random.random(2,3) # 产生一个[2,3]的ndarray
np.random.shuffle(nd2) # 随机打乱nd2中的数据。
nd3 = np.random.uniform(2,3) # 生成均匀分布的随机数
nd4 = np.random.randn(2,3) # 生成标准正态分布的随机数
nd5 = np.random.randint(2,3) # 生成随机的整数numpy中创建特定形状的多维数组
1
2
3
4
5
6
7
8import numpy as np
nd1 = np.zeros([3,3]) # 生成全是0的3x3的矩阵,np.zeros()生成全是0的ndarray
nd2 = np.zeros_like(nd1) # 以ndrr相同维度创建元素为0的数组
nd3 = np.ones_like(nd1) # 以nd1维度创建元素全是1的数组
nd4 = np.empty_like(nd1) # 以nd1维度创建一个空数组
nd5 = np.eye(5) # 该函数用于创建一个5x5的矩阵,对角线为1,其余为0
nd6 = np.full((3,5),666) # 创建3x5的元素全为666的数组,666为指定值保存使用numpy生成的数据
1
2
3
4import numpy as np
nd = np.random.random([5,5])
np.savetxt(X=nd,fname='test.txt') # 保存nd,文件名称为test.txt
nd2 = np.loadtxt('test.txt') # 从test.txt中加载数据利用arange、linspace函数来生成数组
arange是numpy模块中的函数,格式为:arange([start],stop[,step],dtype=None)
其中start与stop用来限定范围,step是步长默认为1,step可以为小数。1
2
3
4import numpy as np
nd = np.arange(10) # np中的内容为[0 1 2 3 4 5 6 7 8 9]
nd1 = np.arange(1,4,0.5) # np中的内容为[1.0 1.5 2.0 2.5 3.0 3.5 4.0]
nd2 = np.aramge(9,-1,-1) # nd2中的内容为[9 8 7 6 5 4 3 2 1 0]linspace也是numpy中常用的函数,格式为:
np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
linspace可以根据输入数据的指定范围以及等份数量,自动生成线性分量。endpoint(包含终点)默认为True。等分量num默认为50,如果将retstep设置为True,则会返回一个带步长的ndarray1
2import numpy as np
print(np.linspace(0,1,10)) # 产生10个数,间隔为0.111111获取数据。
数据生成后,如何读取数据,常用数据的的方法。(类似于python数据切片的方法)1
2
3
4
5
6
7
8
9import numpy as np
np.random.seed(2024)
nd = np.random.random([10]) # 产生一维的10个数据点
nd[3] # 获取指定位置的数据,获取第4个元素
nd[3:6] # 截取一段数据
nd[1:6:2] # 获取固定间隔的数据
nd[::-2] # 倒序取数
nd2 = np.arange(25).reshape([5,5]) # 产生一个25个数据点的一维数据,而后通过reshape进行形状重整为[5,5]
nd2[:,1:3] # 截取多维数组中,指定的列,读取第2,3列。Numpy的算术运算
在机器学习和深度学习中,涉及大量的数组或矩阵运算,这里介绍两种常用的运算。一种是对应元素相乘,又称逐元乘法(Element-Wisr Product)运算符为np.multiply()或*。一种是点积或内积元素,运算符为np.dot()
逐元乘法
1 | |
点积运算(Dot Product)又可以称为内积,在Numpy用np.dot表示
1 | |
- 数组变形
在机器学习和深度学习任务中,通常需要将处理好的数据以模型能够接收的格式进行输入,然后进行一系列运算,最终返回一个处理结果。然而由于不同模型所接受的输入格式不一样,往往需要先对其进行一系列变形和运算,从而将数据处理成符合模型要求的格式。
更改数组的形状。方法有1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# arr.reshape(),将向量arr维度进行改变,不修改向量本身
# arr.resize(), 重新将向量arr维度进行改变,修改向量本身
# arr.T ,对向量进行转置
# arr.ravel ,对向量arr进行展平,即将多维数组变成1维数组,不会产生原数组的副本
# arr.flatten,对向量arr进行展平,即将多维数值变成1维数组,返回原数组的副本
# arr.squeeze(), 只能对维度为1的进行降维。对多维数组使用时不会进行任何报错,但是不会产生任何影响
# arr.transpose,对高维矩阵进行轴转换
import numpy as np
arr = np.arange(10)
print(arr.reshape(2,5))
# 指定维度时可以只指定行数和列数,其他用-1代替
print(arr.reshape([5,-1]))
print(arr)
print(arr.reshape([-1,5]))
#结果[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
arr [0 1 2 3 4 5 6 7 8 9] # 没有对arr本身进行修改
[[0 1 2 3 4]
[5 6 7 8 9]]
使用resize来修改向量维度,
1 | |
向量转置 ,T
1 | |
向量展平.ravel
1 | |
矩阵转换为向量,这种需求经常出现在卷积神经网络与全连接之间,用于数据的展平,flatten
1 | |
降维操作,我也是经常使用的一个方法,squeeze 主要用来降维,把矩阵中含有1的维度去掉,在pytorch中还有一种与之相反的一种操作,torch.unsqueeze()
1 | |
高维转换,transpose,这个在深度学习中经常使用,比如把RGB转换为GBR
1 | |
- 合并数组
1
2
3
4
5
6# np.append ,内存占用大
# np.concatenate 没有内存占用问题
# np.stack, 沿着新的轴加入一系列数组
# np.hstack ,堆栈数组垂直顺序(行)
# np.vstack ,堆栈数组垂直顺序(列)
# 对于append 和concatenate ,待合并的数组必须有相同的行数或列数(满足一个即可)
append合并一维数组
1 | |
合并多维数组
1 | |
concatenate沿指定轴连接数组或矩阵
1 | |
stack 沿着固定轴堆积或矩阵
1 | |
通用函数
sqrt ,计算序列化数据的平方根
sin,cos 三角函数
abs , 计算序列化数据的绝对值
dot, 矩阵运算
log,log10,log2, 对数函数
exp, 指数函数
cumsum,cumproduct , 累计求和,求积
sum ,对一个序列化数据进行求和
mean , 计算均值
median ,计算中位数
std , 计算标准差
var , 计算方差1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import time
import math
import numpy as np
x = [i * 0.001 for i in np.arange(1000000)]
start = time.clock()
for i , t in enumerate(x):
x[i] = math.sin(t)
print('math.sin:',time.clock()-start)
x = [i*0.001 for i in np.arange(100000)]
x = np.array(x)
start =time.clock()
np.sin(x)
print('numpy.sin:',time.clock()-start)广播机制
Numpy 中的Universal functional 中要求输入的数组shape是一致的,当数组的shape不相等时,则会使用广播机制。但是使用广播机制需要满足一定的规则,否则将出错。
1) 让所有输入数组都向其中的shape最长的数组看齐,不足的部分则通过在前面加1补齐。
2) 输出数组的shape是输出数组shape的各个轴上的最大值
- 如果输入数组的某个轴和输出数组的对于长度相同或者某个轴的长度为1时,这个数组能被用来计算,否则出错
4) 当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值。
1 | |
总结
Numpy是深度学习的入门库,学习是很重要的。这里只是列举了一些主要内容,如果想要了解更多的内容,可以登录Numpy官网(http://www.Numpy.org/)查看更多的内容。
挖坑
向量和数组之间的关系是什么?向量的定义是什么?
在数学科物理中,向量被定义为具有大小和方向量。例如速度是一个向量,因为它不仅有大小(数独),还有方向(行进的方向)。
数组是编程中的一种基本数据结构,用于存储一组有序的元素。这些元素可以是任何类型,如整形、浮点数、字符串等。
标量(scalar)是零维只有大小,没有方向的量,如1,2,3
向量(Vector)是一维只有大小和方向的量,如(1,2)。(计算方向的公式为:)
矩阵(Matrix)是二维的向量,[[1, 2], [2, 3]]
张量(Tensor) 按照任意维排列的一堆数字的推广。矩阵不过是三维张量下的一个二维切面。要在三维张量下找到零维张量需要三个维度的坐标来定位。(注:张量可以是多维的)
矩阵是什么,作用是什么?如何实现矩阵的加减乘除
- 矩阵是一个二维数组,由行和列的元素组成。在数学中,矩阵通常用大写字母表示,如 A,B 等,矩阵中的元素通常用小写字母表示,如aij,表示矩阵 A 的第 i 行第 j 列的元素。
- 矩阵可以用来表示线性变换,解决线性方程组,或者表示图形的变换。在数据科学和机器学习中,矩阵通常用于存储和操作大量的数据。
实现矩阵的加减乘除。
加法:两个矩阵相加,只有在它们的行数和列数都相等时才是定义的。结果矩阵的每个元素是相应的元素相加的结果。例如,如果A = aij 和B = bij 是同样大小的矩阵,那么它们的和C = [ cij ]是矩阵 ,其中cij = aij + bij。对应相加
减法:矩阵的减法与加法类似,只有在两个矩阵的行数和列数都相等时才是定义的。结果矩阵的每个元素是相应的元素相减的结果。
乘法:矩阵的乘法比较复杂。如果A 是一个 m×n 的矩阵,B 是一个n×p 的矩阵,那么它们的乘积 AB 是一个 m×p 的矩阵,其元素由A 的行和 B 的列的对应元素的乘积之和给出。
除法:在矩阵中,通常不直接定义除法。但是,我们可以通过乘以逆矩阵来实现类似的效果。如果A是一个可逆的(也就是说,存在一个矩阵 (A-1)使得,A(A-1) = (A-1)A = I其中 𝐼I 是单位矩阵),那么我们可以定义B/A为(BA-1),即是B矩阵除以A矩阵等于B乘以A矩阵的转置。但是,请注意,不是所有的矩阵都是可逆的。
1 | |
傅里叶变换是什么?原理是这样的,怎么实现?(这里开一个新坑,数字信号处理)
基本介绍。
傅里叶变换是一种在数学、物理和工程中广泛使用的数学变换,它可以将一个函数或信号从其原始的时间或空间表示转换为频率表示。这对于许多应用都非常有用,因为它可以揭示信号的频率成分,这在原始的时间或空间表示中可能不明显。
傅里叶变换的基本思想是,任何函数都可以表示为一系列正弦波和余弦波的叠加。换句话说,我们可以将一个复杂的信号分解为一系列更简单的正弦波和余弦波。
原理介绍
傅里叶变换的基本原理是将一个函数或信号从其原始的时间或空间表示转换为频率表示。这是通过将函数表示为一系列正弦波和余弦波的叠加来实现的。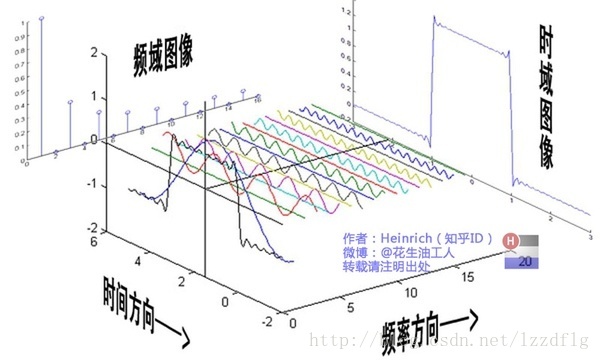
1 | |
什么是对象? 封装,继承,多态是什么?
什么是对象?
在面向对象编程(Object-Oriented Programming,OOP)中,对象是类的实例。类是一种抽象的概念,用于描述具有相似属性和行为的对象的集合。对象是类的具体实现,它具有类定义的属性和方法。
对象可以看作是现实世界中的实体或概念在程序中的表示。每个对象都有自己的状态(属性)和行为(方法),并且可以与其他对象进行交互。
封装
封装是面向对象编程的一种重要概念,它将数据和操作数据的方法捆绑在一起,形成一个称为类的单个实体。封装隐藏了数据的内部实现细节,只暴露对外部可见的接口。这样可以保护数据的完整性,并提供更好的代码组织和维护性。
通过封装,对象的内部状态可以被保护起来,只能通过公共接口进行访问和修改。这样可以防止对数据的不合理访问和修改,增加了代码的安全性和可靠性。
继承
继承是面向对象编程中的另一个重要概念,它允许一个类继承另一个类的属性和方法。继承创建了一个类的层次结构,其中一个类(称为子类或派生类)可以从另一个类(称为父类或基类)继承属性和方法。
通过继承,子类可以继承父类的特性,并且可以添加自己的特定特性。这样可以实现代码的重用和扩展,减少了重复编写代码的工作量。
多态
多态是面向对象编程中的另一个重要概念,它允许使用统一的接口来处理不同的对象类型。多态性允许同一个方法在不同的对象上产生不同的行为。
通过多态,可以编写通用的代码,可以处理多个不同类型的对象,而无需针对每种类型编写特定的代码。这提高了代码的灵活性和可扩展性。
1 | |
python中的不同代码高亮表示什么?
在Python的IDLE编程环境中,不同颜色的文本表示不同的含义。以下是IDLE中常见的颜色及其含义:
黑色:普通的代码文本。
蓝色:关键字,例如if、else、for、while等。
绿色:字符串文本。
红色:语法错误或代码中的错误。
紫色:函数和方法的名称。
棕色:数字。
橙色:内置函数和模块的名称。
灰色:注释。
怎么对通道数位置的npy数据进行叠加
思路分析,
x = np.array([1 , 2]) # shape为(1,2)
y = np.array([3 , 4]) # shape为(1,2)
怎么叠加np为[[1 , 2],[3 ,4]] #shape为(2,2)
1 | |
堆栈数组垂直顺序(行)
1 | |