图像处理-数据预处理
基本知识
在深度学习中,图像数据通常以多维数组(在Python中通常使用Numpy数组)的形式表示,这个数组的形状(shape)取决于图像的维度和颜色通道数。
灰度图像:对于灰度图像(也就是黑白图像),shape通常是两维的,表示图像的高度和宽度。例如,一个256x256像素的灰度图像的shape将是(256, 256)。灰度图像的像素值通常在0到255之间,其中0表示黑色,255表示白色,中间的值表示不同的灰度级别。这是因为每个像素通常由8位(一个字节)表示,所以可以有256(即$2^8$)个不同的可能值。然而,这并不是唯一的表示方式。有时,为了方便计算,我们可能会将像素值归一化到0到1之间。在这种情况下,0仍然表示黑色,1表示白色,中间的值表示不同的灰度级别。
彩色图像:对于彩色图像,通常使用RGB(红,绿,蓝)三个颜色通道,所以shape是三维的。例如,一个256x256像素的RGB彩色图像的shape将是(256, 256, 3)。这里的3代表三个颜色通道。彩色图像通常由三个颜色通道组成:红色(R),绿色(G)和蓝色(B)。每个通道的像素值通常在0到255之间,其中0表示该颜色的完全缺失,255表示该颜色的最大强度。所以,一个RGB颜色图像的像素值范围在理论上是0到255的三维空间,即(0,0,0)到(255,255,255)。同样,有时我们也会将每个颜色通道的像素值归一化到0到1之间。在这种情况下,(0,0,0)表示黑色,(1,1,1)表示白色,其他值表示不同的颜色。需要注意的是,虽然RGB是最常用的颜色空间,但也有其他的颜色空间,如HSV(色相,饱和度,亮度)或者CMYK(青色,品红,黄色,黑色),它们的取值范围可能会有所不同。
图像批量:在深度学习中,我们通常会一次处理多个图像,这就是所谓的批量(batch)。在这种情况下,图像数据的shape将是四维的:(批量大小, 高度, 宽度, 颜色通道数)。例如,如果我们有32个256x256像素的RGB图像,那么这个批量的shape将是(32, 256, 256, 3)。
显示彩色图像
1 | |

对图像进行截取操作
剪裁图片
1 | |
结果图片

1 | |
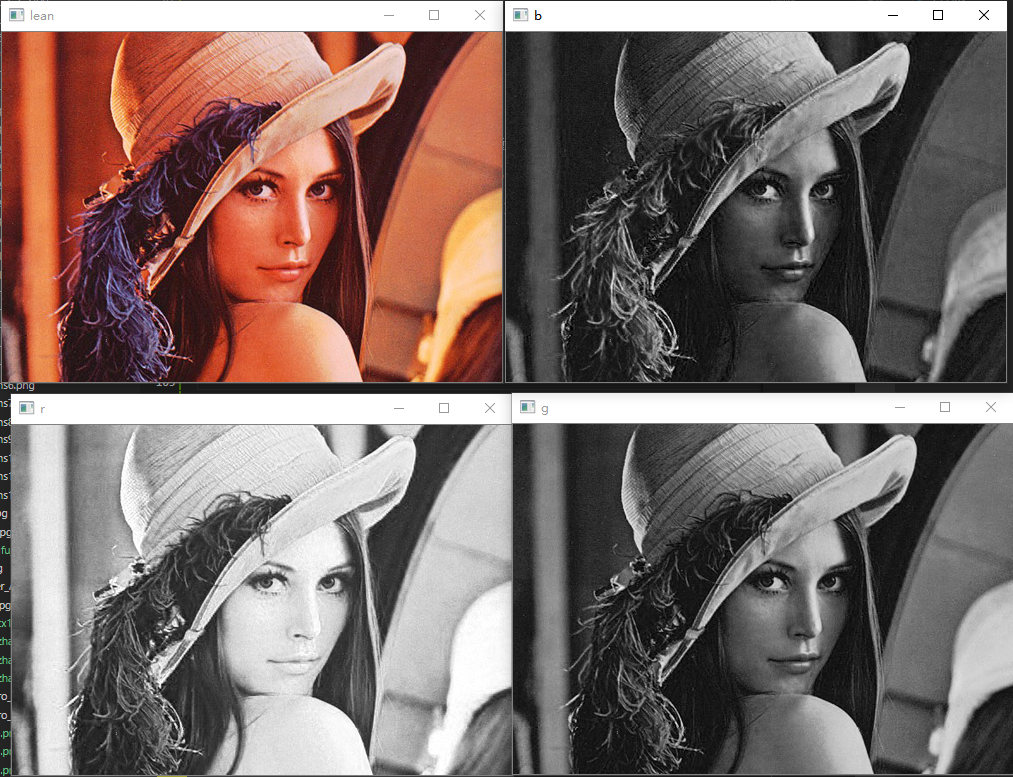
显示RGB通道的图片内容
1 | |
1 | |
对图片进行缩放
1 | |
1 | |
对图片进行形态学操作
掌握图像形态学的基本原理和常用算法。学会使用形态学操作进行图像处理,如噪声去除、边缘检测、特征提取等。培养分析和解决图像处理问题的能力。
1 | |
处理方法
- 二值化处理:这是最基本的阈值处理方法。对于每个像素,我们选择一个阈值。如果像素值大于阈值,我们将其设置为一个值(通常是白色),如果像素值小于或等于阈值,我们将其设置为另一个值(通常是黑色)。这样我们就得到了一个二值图像。
- 反二值化处理:这是二值化处理的反向操作。如果像素值大于阈值,我们将其设置为一个值(通常是黑色),如果像素值小于或等于阈值,我们将其设置为另一个值(通常是白色)。
- 截断阈值处理:对于每个像素,如果其值大于阈值,我们将其设置为阈值。如果像素值小于或等于阈值,我们保持其原值不变。
- 超阈值零处理:对于每个像素,如果其值大于阈值,我们保持其原值不变。如果像素值小于或等于阈值,我们将其设置为零。
- 低阈值零处理:这是超阈值零处理的反向操作。如果像素值大于阈值,我们将其设置为零。如果像素值小于或等于阈值,我们保持其原值不变。
- 自适应阈值处理:这是一种更复杂的方法,它不使用固定的阈值。相反,它根据像素周围的小区域计算阈值。因此,对于同一张图片上的不同区域,我们可以有不同的阈值。这对于当图像的光照条件变化很大时,例如,一半是明亮的,一半是暗淡的图像,非常有用。
实现代码
1 | |







挖更大的坑,opencv库。
彩色图像怎么转换为二维图像的?
首先灰度图像中的一个像素点的范围为0-255,彩色图像可以理解为3个灰度图重合。
需要深度解析代码中的含义,比如一个参数有什么用处。
使用权重标记人脸
1 | |