论文思路——数据预处理
目前的数据预处理有
This may be time-domain features(时域特征)45——2021年
- absolute band power(绝对功率谱)
- Discrete Wavelet Transform (离散小波变换)37-2022-IEEE
- permutation entropy (排列熵) or spectral entropy (熵谱)[21-2021-Complexity of EEG dynamics for early diagnosis of Alzheimer’s disease using permutation entropy neuromarker,’’ C]
- coherence anaylysis features (相干性分析) such as spectrall coherece(光谱相干性)
- RBP (注:按照下面的频率划分,the shape of data is [T , B ,C]=[T, 5, C],Delta: 0.5 – 4 Hz Theta: 4 – 8 Hz Alpha: 8 – 13 Hz Beta: 13-25 Hz Gamma: 25-45 Hz,或许这个数据预处理的方法会生效 )
- spectral coherence connectivity (光谱相干性,光谱相干性建立在PSD,PSD是功率谱密度)
- FFT (Fast Fourier Transform) 快速傅里叶变换
数据预处理组合思路
- Morlet Wavelet Transform ——> RBP
- Welch PSD ——> SSC
需要注意的前提知识。
- AD patients may exhaibit changes in the EEG signal, such as reduced(减少) alpha power (Alpha: 8 – 13 Hz ) and increased (增加) theta power (: 4 – 8 Hz).39-2021-Clinical Neurophysiology-3区
It can be visually observed that AD group has lower delta connectivity than CN group in multiple brain locations.This finding is supported by the literature [53-2016]https://www.sciencedirect.com/science/article/pii/S1388245715009839() - Train, validation and test sets are created.
- The time frequency transforms and the feature extraction steps were implemented in Python 3.10 using the MNE library.
- GFlops (计算量)
- hyperparameters (超参数)
挖坑
怎么计算模型的计算量。
1 | |
看论文的心态
Because it is an English paper, there is a kind of resistance. Take your time.
由于是英文论文,有种抗拒的心态。慢慢看吧。
代码实现
FFT快速傅里叶变换参考博客
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34import os
import numpy as np
from tqdm import tqdm
# 定义输入和输出文件夹路径
input_folder = 'data_cut_npy/AD' # 输入文件夹路径,包含要进行 FFT 变换的 .npy 文件
output_folder = 'data_FFT_npy/AD' # 输出文件夹路径,用于保存变换后的数据
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 获取输入文件夹中的所有 .npy 文件
file_list = os.listdir(input_folder)
npy_files = [file for file in file_list if file.endswith('.npy')]
# 遍历每个 .npy 文件进行 FFT 变换并保存
for file_name in tqdm(npy_files, desc='Processing', unit='file'):
# 读取 .npy 文件
file_path = os.path.join(input_folder, file_name)
data = np.load(file_path)
# 对数据中的每一行进行 FFT 变换
fft_data = np.apply_along_axis(np.fft.fft, axis=0, arr=data)
# 获取 FFT 结果的幅值
fft_magnitude = np.abs(fft_data)
# 构造输出文件路径
output_file_name = file_name.replace('.npy', '_fft.npy')
output_file_path = os.path.join(output_folder, output_file_name)
# 保存 FFT 结果
np.save(output_file_path, fft_magnitude)RBP 按频率划分[T, C, B]
什么是时域和频域
参考资料
原始的EEG数据是由很多个样本点数所构成的一个有限的离散的时间序列数据。至于样本点数的多少,则由采样率所决定,比如采样率为1000Hz,那么每秒就有1000个数据样本点。其中,每个样本点数据代表的是脑电波幅的大小,物理学上称为电压值,单位为伏特(V),由于脑电信号通常较弱,所以更常使用的单位为微伏(uV)。
1 | |
赫兹(HZ)的定义是什么?
Hz 是频率的单位。频率是指电脉冲,交流电波形,电磁波,声波和机械的振动周期循环时,1秒钟重复的次数。1Hz代表每秒钟周期震动1次,60Hz代表每秒周期震动60次。
对于声音,人类的听觉范围为20Hz~20000Hz,低于这个范围叫做次声波,高于这个范围的叫做超声波。
0. 提取set文件
1 | |
AD交集
1 | |
检查通道
1 | |
第二版
1 | |
数据预处理- 留一法验证
随机划分数据集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53import os
import shutil
import random
# 指定包含数据文件的文件夹列表
data_folders = [
"guding_channl/AD",
"guding_channl/CN",
"guding_channl/MCI"
]
# 对应的保存训练集和测试集的文件夹路径
train_folders = [
"data/train/AD",
"data/train/CN",
"data/train/MCI"
]
test_folders = [
"data/test/AD",
"data/test/CN",
"data/test/MCI"
]
# 确保输入和目标文件夹数量匹配
assert len(data_folders) == len(train_folders) == len(test_folders), "输入文件夹和目标文件夹数量不匹配"
# 遍历每个数据文件夹
for data_folder, train_folder, test_folder in zip(data_folders, train_folders, test_folders):
# 创建保存训练集和测试集的文件夹
os.makedirs(train_folder, exist_ok=True)
os.makedirs(test_folder, exist_ok=True)
# 获取数据文件夹中的所有文件
data_files = os.listdir(data_folder)
# 遍历数据文件夹中的文件
for file_name in data_files:
source_file = os.path.join(data_folder, file_name)
try:
# 以8:2的比例将文件分配到训练集或测试集
if random.random() < 0.9:
shutil.copy(source_file, train_folder)
else:
shutil.copy(source_file, test_folder)
except Exception as e:
print(f"无法复制文件 {file_name}: {e}")
# 打印训练集和测试集的文件数量
print(f"{data_folder} -> 训练集大小:", len(os.listdir(train_folder)))
print(f"{data_folder} -> 测试集大小:", len(os.listdir(test_folder)))选取固定通道数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93import os
import mne
import numpy as np
# 定义所需通道的列表
channels = ['C3', 'Fz', 'F8', 'F4', 'C4', 'F3', 'Pz', 'P4', 'Cz', 'P3', 'F7']
# 输入和输出文件夹路径列表
input_folders = ['data/AD', 'data/MCI', 'data/NC', '公开数据集/AD', '公开数据集/CN']
output_folders = ['guding_channl/AD', 'guding_channl/MCI', 'guding_channl/CN', 'guding_channl/AD', 'guding_channl/CN']
# 定义函数来处理EDF文件
def process_edf_file(file_path, output_folder):
# 读取EDF文件
raw = mne.io.read_raw_edf(file_path, preload=True)
# 检查通道数量
if not all(ch in raw.ch_names for ch in channels):
print(f"文件 {file_path} 不包含所有所需通道,跳过处理。")
return
# 删除不需要的通道,只保留指定的通道
raw.pick_channels(channels)
# 按照指定顺序重新排列通道
raw.reorder_channels(channels)
# 获取处理后的EEG数据
eeg_data = raw.get_data()
# 获取文件名(不包含扩展名)
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 构建保存路径
save_path = os.path.join(output_folder, f'{file_name}_processed.npy')
# 保存处理后的EEG数据为npy文件
np.save(save_path, eeg_data)
print(f"处理并保存文件: {save_path}")
# 定义函数来处理SET文件
def process_set_file(file_path, output_folder):
# 读取SET文件
raw = mne.io.read_raw_eeglab(file_path, preload=True)
# 检查通道数量
if not all(ch in raw.ch_names for ch in channels):
print(f"文件 {file_path} 不包含所有所需通道,跳过处理。")
return
# 删除不需要的通道,只保留指定的通道
raw.pick_channels(channels)
# 按照指定顺序重新排列通道
raw.reorder_channels(channels)
# 获取处理后的EEG数据
eeg_data = raw.get_data()
# 获取文件名(不包含扩展名)
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 构建保存路径
save_path = os.path.join(output_folder, f'{file_name}_processed.npy')
# 保存处理后的EEG数据为npy文件
np.save(save_path, eeg_data)
print(f"处理并保存文件: {save_path}")
# 定义函数来处理文件,根据文件后缀选择处理方法
def process_file(file_path, output_folder):
file_extension = os.path.splitext(file_path)[1]
if file_extension == '.edf':
process_edf_file(file_path, output_folder)
elif file_extension == '.set':
process_set_file(file_path, output_folder)
else:
print(f"文件 {file_path} 格式不支持,跳过处理。")
# 确保文件夹数量相同
assert len(input_folders) == len(output_folders), "输入和输出文件夹数量不匹配"
# 创建新文件夹
for output_folder in output_folders:
os.makedirs(output_folder, exist_ok=True)
# 遍历每个输入文件夹
for input_folder, output_folder in zip(input_folders, output_folders):
for file_name in os.listdir(input_folder):
file_path = os.path.join(input_folder, file_name)
# 根据文件后缀选择处理方法
process_file(file_path, output_folder)剪切数据集代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import os
import numpy as np
from tqdm import tqdm
# 指定包含原始npy文件的文件夹路径列表
input_folders = ['data/test/AD', 'data/test/CN','data/test/MCI','data/train/AD', 'data/train/CN','data/train/MCI'] # 输入文件夹列表
output_folders = ['data_npy_cut/test/AD', 'data_npy_cut/test/CN','data_npy_cut/test/MCI','data_npy_cut/train/AD', 'data_npy_cut/train/CN','data_npy_cut/train/MCI'] # 对应的输出文件夹列表
# 确定剪切后的数据长度
cut_length = 2048
# 确保输出文件夹存在
for output_folder in output_folders:
os.makedirs(output_folder, exist_ok=True)
# 遍历文件夹列表
for input_folder, output_folder in zip(input_folders, output_folders):
for file_name in os.listdir(input_folder):
if file_name.endswith('.npy'):
# 加载原始npy文件
data = np.load(os.path.join(input_folder, file_name))
# 确定剪切的段数
num_cuts = data.shape[1] // cut_length
# 使用tqdm显示进度条
for i in tqdm(range(num_cuts), desc=f'Processing {file_name} in {input_folder}', unit='cut'):
cut_data = data[:, i * cut_length : (i + 1) * cut_length]
np.save(os.path.join(output_folder, f'{file_name[:-4]}_cut_{i}.npy'), cut_data)固定训练数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44import os
import csv
import numpy as np
train_path = "train_data.csv"
val_path = "test_data.csv"
def create_data_text(path):
"""建立数据data列表,划分数据集"""
f_train = open(train_path, "w", newline='')
f_val = open(val_path, "w", newline='')
train_writer = csv.writer(f_train)
val_writer = csv.writer(f_val)
# 遍历 'train' 文件夹
train_dir = os.path.join(path, 'train')
for cls, dirname in enumerate(os.listdir(train_dir)):
class_path = os.path.join(train_dir, dirname)
if os.path.isdir(class_path):
flist = os.listdir(class_path)
np.random.shuffle(flist)
fnum = len(flist)
for i, filename in enumerate(flist):
train_writer.writerow([os.path.join(class_path, filename), str(cls)])
# 遍历 'test' 文件夹
test_dir = os.path.join(path, 'test')
for cls, dirname in enumerate(os.listdir(test_dir)):
class_path = os.path.join(test_dir, dirname)
if os.path.isdir(class_path):
flist = os.listdir(class_path)
np.random.shuffle(flist)
fnum = len(flist)
for i, filename in enumerate(flist):
val_writer.writerow([os.path.join(class_path, filename), str(cls)])
f_train.close()
f_val.close()
if __name__ == "__main__":
create_data_text("data_npy_cut")十折交叉验证
1 | |
数据增强
mne库的文档链接链接
pywt库的
3. 连续小波变换 + RBP + 绘制图像的代码
1 | |
1 | |
增强的数据代码
1 | |
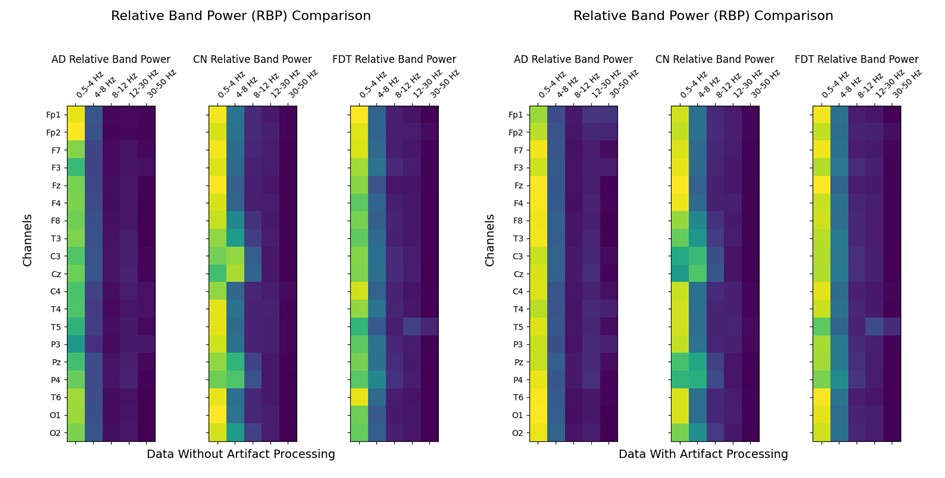
CWT + RBP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64import os
import numpy as np
import pywt
from tqdm import tqdm
# 采样频率
fs = 500
# 输入和输出文件夹路径列表
input_folders = ['data_npy_cut/train/AD/', 'data_npy_cut/train/CN/','data_npy_cut/train/FDT/']
output_folders = ['CWT-RBP/train/AD', 'CWT-RBP/train/CN','CWT-RBP/train/FDT']
# 确保文件夹数量相同
assert len(input_folders) == len(output_folders), "输入和输出文件夹数量不匹配"
# 创建新文件夹
for output_folder in output_folders:
os.makedirs(output_folder, exist_ok=True)
# 小波函数
wavelet = 'morl'
# 定义 CWT 的频率范围
freq_ranges = [(0.5, 4), (4, 8), (8, 13), (13, 25), (25, 45)]
scales = np.arange(1, 128)
def calculate_rbp(cwt_coeffs, freq_band, scales, fs):
min_scale = np.min(np.where((fs / (scales * 2)) <= freq_band[1]))
max_scale = np.max(np.where((fs / (scales * 2)) >= freq_band[0]))
band_power = np.sum(np.abs(cwt_coeffs[min_scale:max_scale + 1, :])**2, axis=0)
total_power = np.sum(np.abs(cwt_coeffs)**2, axis=0)
return band_power / total_power
# 遍历输入文件夹
for input_folder, output_folder in zip(input_folders, output_folders):
for file_name in tqdm(os.listdir(input_folder)):
if file_name.endswith('.npy'):
# 读取 .npy 文件
data = np.load(os.path.join(input_folder, file_name))
# 提取不同频段的数据
data_freq_bands = []
for ch_data in data:
ch_data_freq_band = []
# 计算 CWT 系数
cwt_coeffs, _ = pywt.cwt(ch_data, scales, wavelet, sampling_period=1/fs)
for fmin, fmax in freq_ranges:
# 计算频段的相对功率谱密度 (RBP)
rbp = calculate_rbp(cwt_coeffs, (fmin, fmax), scales, fs)
ch_data_freq_band.append(rbp)
data_freq_bands.append(ch_data_freq_band)
# 重塑数据形状为 [5, 19, 2500]
data_freq_bands = np.array(data_freq_bands)
data_freq_bands = np.transpose(data_freq_bands, (0, 1, 2)) # [5, 19, 2500]
# 修改文件名,添加处理方法标记
output_file_name = os.path.splitext(file_name)[0] + '_cwt_rbp.npy'
output_file_path = os.path.join(output_folder, output_file_name)
# 保存处理后的数据
np.save(output_file_path, data_freq_bands)FTBT + BRP
FTBT1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50import os
import numpy as np
from scipy.fftpack import fft, ifft
from tqdm import tqdm
# 采样频率
fs = 500
# 输入和输出文件夹路径列表
input_folders = ['data_npy_cut/train/AD/', 'data_npy_cut/train/CN/','data_npy_cut/train/FDT/']
output_folders = ['FBFT/train/AD', 'FBFT/train/CN','FBFT/train/FDT']
# 确保文件夹数量相同
assert len(input_folders) == len(output_folders), "输入和输出文件夹数量不匹配"
# 创建新文件夹
for output_folder in output_folders:
os.makedirs(output_folder, exist_ok=True)
def fbft(signal):
N = len(signal)
forward_fft = fft(signal)
backward_fft = fft(ifft(forward_fft))
fbft_result = forward_fft + backward_fft
return fbft_result
# 遍历输入文件夹
for input_folder, output_folder in zip(input_folders, output_folders):
for file_name in tqdm(os.listdir(input_folder)):
if file_name.endswith('.npy'):
# 读取 .npy 文件
data = np.load(os.path.join(input_folder, file_name))
# 对每个通道的数据进行 FBFT 操作
fbft_data = []
for ch_data in data:
fbft_ch_data = fbft(ch_data)
fbft_data.append(fbft_ch_data)
# 将结果转换为 numpy 数组
fbft_data = np.array(fbft_data)
# 修改文件名,添加处理方法标记
output_file_name = os.path.splitext(file_name)[0] + '_fbft.npy'
output_file_path = os.path.join(output_folder, output_file_name)
# 保存处理后的数据
np.save(output_file_path, fbft_data)
使用matlab代码对数据进行CWT变换
1 | |
堆叠+横轴
1 | |
图片转换为npy数据格式,二值化输入
1 | |
任务寻找预处理代码
在paperwithcode上。
DWT 算法对将时间域上的数据转换为频率能量上的数据,找到这样的代码。
连续的小波变换 :CWT
离散的小波变换 :DWT
小波变换的基本知识:
不同的小波基函数,是由同一个基本小波函数经缩放和平移生成的。
小波变换是将原始图像与小波基函数以及尺度函数进行内积运算, 所以一个尺度函数和一个小波基函数就可以确定一个小波变换。PSD
参考链接
mne怎么使用
mne函数psd——array-welch介绍
mne函数psd-array-welch使用例子
提取通道位置, TP9,AF7,AF8,TP10
[‘Fp1’, ‘Fp2’, ‘F7’, ‘F3’, ‘Fz’, ‘F4’, ‘F8’, ‘T3’, ‘C3’, ‘Cz’, ‘C4’, ‘T4’, ‘T5’, ‘P3’, ‘Pz’, ‘P4’, ‘T6’, ‘O1’, ‘O2’]
1 | |
划分数据集
1 | |
填坑
train-loss 和test-loss之间的关系
变化趋势分析:train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的)train loss 不断下降,test loss趋于不变,说明网络过拟合;train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset)train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题;(最不好的情况)train_loss 不断下降, test_loss 不断上升,和第2种情况类似说明网络过拟合了。
调高batch——size有提高点的趋势 32好于 0.0005的参数。
动态调整学习率
使用 StepLR、ExponentialLR 或 ReduceLROnPlateau
StepLR
1 | |
ExponentialLR 以指数方式衰减学习率。
1 | |
ReduceLROnPlateau 在监测指标停滞时降低学习率,适用于验证损失等指标。
1 | |
- 替换模型的输出层
1 | |
| batch-size | learning |
| 16 | 0.00005 |
| 8 | 0.00005 |
| 32 | 0.001 |
| time | wight_size | in_feature |
| 3 | 1536 | 96 |
| 4 | 2048 | 128 |
| 5 | 2560 | 160 |
| 6 | 3072 | 192 |
| 7 | 3584 | 224 |
| 8 | 4096 | 256 |
| 9 | 4608 | 288 |
| 10 | 5120 | 320 |
| 11 | 5632 | 352 |
| 12 | 6144 | 384 |
| 13 | 6656 | 416 |
密码
Qwer123@
Qwer123.
train-loss 和test-loss之间的关系
变化趋势分析:train loss 不断下降,test loss不断下降,说明网络仍在学习;
(最好的)train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
(检查dataset)train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
(减少学习率)train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题;(最不好的情况)train_loss 不断下降, test_loss 不断上升,和第2种情况类似说明网络过拟合了。