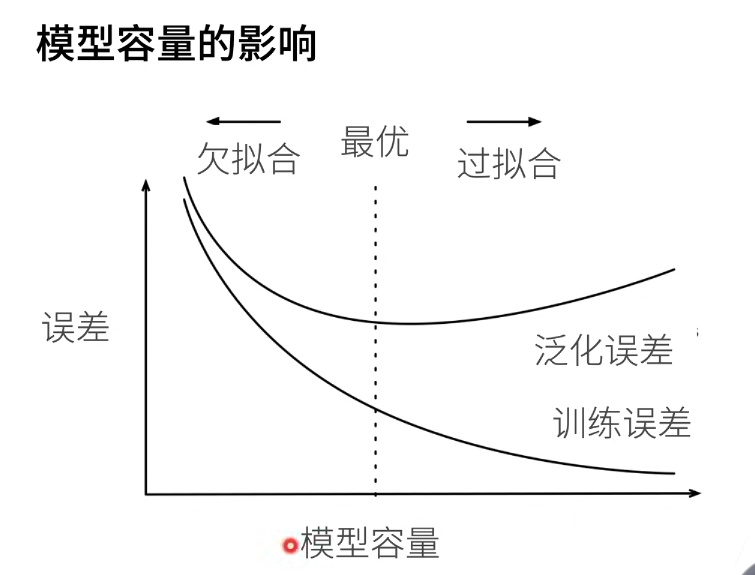
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
|
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms
from tqdm import tqdm
from dataset import EEGDataset, transform1,transform3
from net import IntegratedNet
from sklearn.metrics import classification_report
from matplotlib import pyplot as plt
import logging
logging.basicConfig(filename='training.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def train_identityformer_model(model, model_name, num_epochs=100, num_classes=3, batch_size=8, learning_rate=0.0005, w_wight=2560, chennal=32,load =False):
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
m = nn.Softmax(dim=1)
train_dataset = EEGDataset(csv_file='train_data.csv', transform=transform1)
test_dataset = EEGDataset(csv_file='test_data.csv', transform=transform1)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
save_dir = os.path.join('model', model_name)
os.makedirs(save_dir, exist_ok=True)
if load == True:
model.load_state_dict(torch.load('三分类预训练模型-0.99.pth'))
best_val_acc = 0
best_model_path = os.path.join(save_dir, "{}_best_model.pth".format(model_name))
train_loss_arr = []
train_acc_arr = []
val_loss_arr = []
val_acc_arr = []
early_stop = False
patience = 5
counter = 0
for epoch in range(num_epochs):
train_loss_total = 0
train_acc_total = 0
val_loss_total = 0
val_acc_total = 0
model.train()
for i, (train_x, train_y) in enumerate(tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")):
train_x = train_x.to(device)
train_y = train_y.to(device)
train_x = train_x.unsqueeze(1)
train_x = train_x.view(batch_size, 1, chennal, w_wight)
train_y_pred = model(train_x)
train_loss = loss_fn(train_y_pred, train_y)
train_acc = (m(train_y_pred).max(dim=1)[1] == train_y).sum()/train_y.shape[0]
train_loss_total += train_loss.data.item()
train_acc_total += train_acc.data.item()
train_loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss_arr.append(train_loss_total / len(train_loader))
train_acc_arr.append(train_acc_total / len(train_loader))
print("epoch:{} train_loss:{} train_acc:{}".format(epoch, train_loss_arr[-1], train_acc_arr[-1]))
model.eval()
for j, (val_x, val_y) in enumerate(test_loader):
val_x = val_x.to(device)
val_y = val_y.to(device)
val_x = val_x.unsqueeze(1)
val_x = val_x.view(batch_size, 1, chennal, w_wight)
val_y_pred = model(val_x)
val_loss = loss_fn(val_y_pred, val_y)
val_acc = (m(val_y_pred).max(dim=1)[1] == val_y).sum()/val_y.shape[0]
val_loss_total += val_loss.data.item()
val_acc_total += val_acc.data.item()
val_loss_arr.append(val_loss_total / len(test_loader))
val_acc_arr.append(val_acc_total / len(test_loader))
print("epoch:{} val_loss:{} val_acc:{}".format(epoch, val_loss_arr[-1], val_acc_arr[-1]))
logging.info(f"Epoch {epoch}: Train Loss: {train_loss_arr[-1]}, Train Acc: {train_acc_arr[-1]}, Val Loss: {val_loss_arr[-1]}, Val Acc: {val_acc_arr[-1]}")
if val_acc_arr[-1] > best_val_acc:
best_val_acc = val_acc_arr[-1]
torch.save(model.state_dict(), best_model_path)
print("保存模型成功!")
counter = 0
else:
counter += 1
if counter >= patience:
print("Early stopping")
early_stop = True
break
np.save(os.path.join(save_dir, f"{model_name}_train_loss.npy"), np.array(train_loss_arr))
np.save(os.path.join(save_dir, f"{model_name}_train_acc.npy"), np.array(train_acc_arr))
np.save(os.path.join(save_dir, f"{model_name}_val_loss.npy"), np.array(val_loss_arr))
np.save(os.path.join(save_dir, f"{model_name}_val_acc.npy"), np.array(val_acc_arr))
if early_stop:
break
print('Training completed!')
model = IntegratedNet(input_size=1, in_feature=320, num_classes=3)
num_epochs = 100
num_classes = 3
batch_sizes = [8,16,16,16]
learning_rates = [0.0005, 0.0005, 0.0005, 0.0005]
chennal = 11
w_wight = 5120
logging.info("Start training")
for i, (learning_rate, batch_size) in enumerate(zip(learning_rates, batch_sizes)):
model_name = f"混合数据集-第{i + 1}次-AD-CN-MCI-10秒-learning-{learning_rate}bitch-{batch_size}"
logging.info(f"Training parameters - Model: {model_name}, Num Epochs: {num_epochs}, Num Classes: {num_classes}, Batch Size: {batch_size}, Learning Rate: {learning_rate}, Chennal: {chennal}, W Weight: {w_wight}")
train_identityformer_model(model, model_name=model_name, num_epochs=num_epochs, num_classes=num_classes, batch_size=batch_size, learning_rate=learning_rate, chennal=chennal, w_wight=w_wight, load=False)
logging.info("Training completed")
|